Managing concurrency of Dagster assets, jobs, and Dagster instances
You often want to control the number of concurrent runs for a Dagster job, a specific asset, or for a type of asset or job. Limiting concurrency in your data pipelines can help prevent performance problems and downtime.
Limit the number of total runs that can be in progress at the same time
- Dagster Core, add the following to your dagster.yaml
- In Dagster+, add the following to your deployment settings
concurrency:
runs:
max_concurrent_runs: 15
Limit the number of runs that can be in progress for a set of ops
You can assign assets and ops to concurrency pools which allow you to limit the number of in progress runs containing those assets or ops. You first assign your asset or op to a concurrency pool using the pool keyword argument.
import time
import dagster as dg
@dg.asset(pool="foo")
def my_asset():
pass
@dg.op(pool="bar")
def my_op():
pass
@dg.op(pool="barbar")
def my_downstream_op(inp):
return inp
@dg.graph_asset
def my_graph_asset():
return my_downstream_op(my_op())
defs = dg.Definitions(
assets=[my_asset, my_graph_asset],
)
You should be able to verify that you have set the pool correctly by viewing the details pane for the asset or op in the Dagster UI.
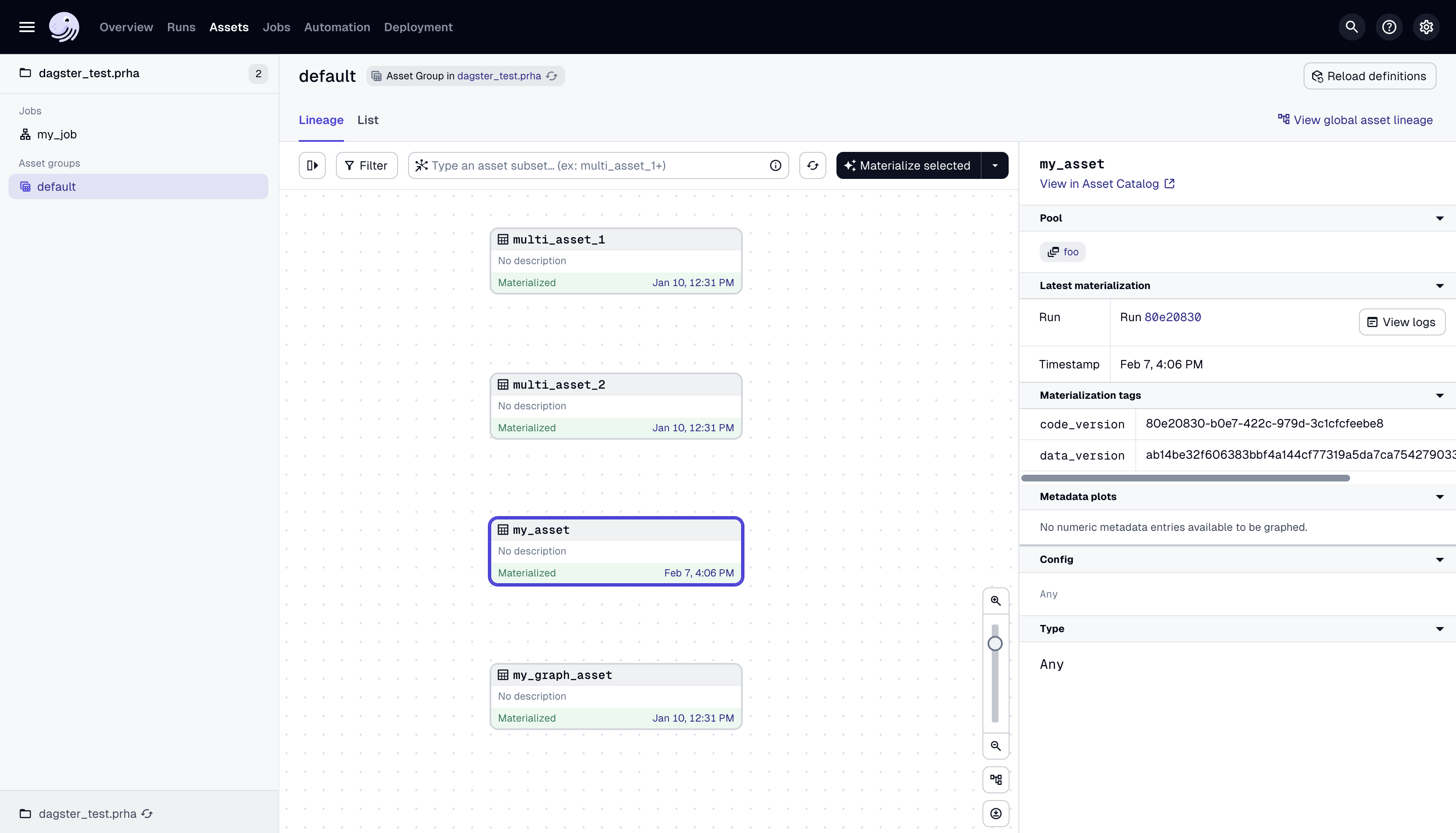
Once you have assigned your assets and ops to a concurrency pool, you can configure a pool limit for that pool in your deployment by using the Dagster UI or the Dagster CLI.
To specify a limit for the pool "database" using the UI, navigate to the Deployments → Concurrency settings page and click the Add pool limit button:
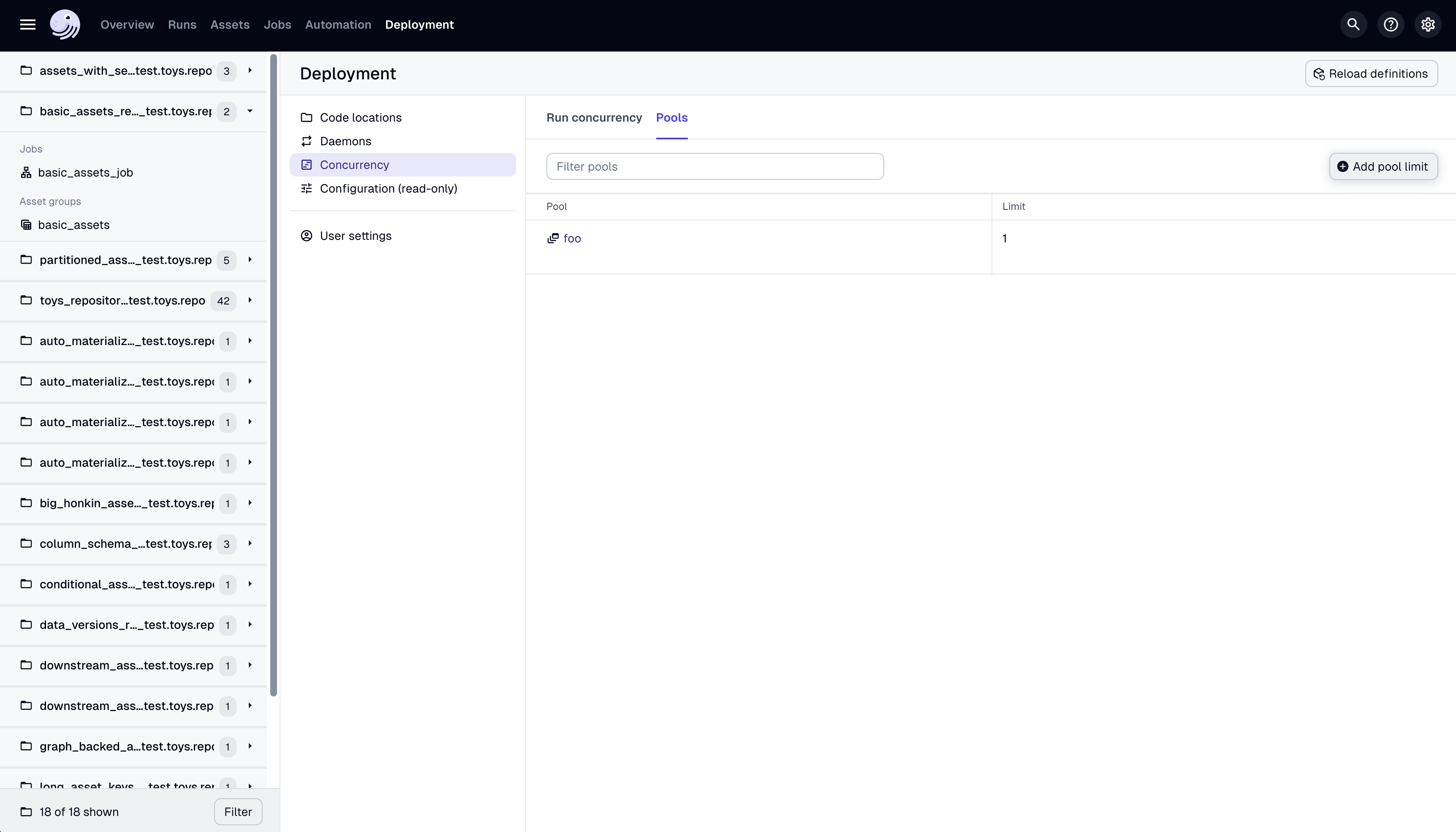
To specify a limit for the pool "database" using the CLI, use:
dagster instance concurrency set database 1
Setting a default limit for concurrency pools
- Dagster+: Edit the
concurrencyconfig in deployment settings via the Dagster+ UI or thedagster-cloudCLI. - Dagster Open Source: Use your instance's dagster.yaml
concurrency:
pools:
default_limit: 1
Limit the number of runs that can be in progress by run tag
You can also limit the number of in progress runs by run tag. This is useful for limiting sets of runs independent of which assets or ops it is executing. For example, you might want to limit the number of in-progress runs for a particular schedule. Or, you might want to limit the number of in-progress runs for all backfills.
concurrency:
runs:
tag_concurrency_limits:
- key: "dagster/sensor_name"
value: "my_cool_sensor"
limit: 5
- key: "dagster/backfill"
limit: 10
Limit the number of runs that can be in progress by unique tag value
To apply separate limits to each unique value of a run tag, set a limit for each unique value using applyLimitPerUniqueValue. For example, instead of limiting the number of backfill runs across all backfills, you may want to limit the number of runs for each backfill in progress:
concurrency:
runs:
tag_concurrency_limits:
- key: "dagster/backfill"
value:
applyLimitPerUniqueValue: true
limit: 10
[Advanced] Limit the number of assets or ops actively in execution across a large set of runs
For deployments with complex jobs containing many ops, blocking entire runs for a small number of concurrency-limited ops may be too coarse-grained for your requirements. Instead of enforcing concurrency limits at the run level, Dagster will ensure that the concurrency limit will be applied at the individual asset or op execution level. This means that if one run completes its materialization of a pool's asset, a materialization of another pool asset in a different run may begin even if the first run is still in progress.
You can set the granularity of the concurrency limit enforcement to be at the op level instead of at the run level:
concurrency:
pools:
granularity: op
Prevent runs from starting if another run is already occurring (advanced)
You can use Dagster's rich metadata to use a schedule or a sensor to only start a run when there are no currently running jobs.
import time
import dagster as dg
@dg.asset
def first_asset(context: dg.AssetExecutionContext):
# sleep so that the asset takes some time to execute
time.sleep(75)
context.log.info("First asset executing")
my_job = dg.define_asset_job("my_job", [first_asset])
@dg.schedule(
job=my_job,
# Runs every minute to show the effect of the concurrency limit
cron_schedule="* * * * *",
)
def my_schedule(context):
# Find runs of the same job that are currently running
run_records = context.instance.get_run_records(
dg.RunsFilter(job_name="my_job", statuses=[dg.DagsterRunStatus.STARTED])
)
# skip a schedule run if another run of the same job is already running
if len(run_records) > 0:
return dg.SkipReason(
"Skipping this run because another run of the same job is already running"
)
return dg.RunRequest()
defs = dg.Definitions(
assets=[first_asset],
jobs=[my_job],
schedules=[my_schedule],
)
Troubleshooting
When limiting concurrency, you might run into some issues until you get the configuration right.
Runs going to STARTED status and skipping QUEUED
This only applies to Dagster Open Source.
The run_queue key may not be set in your instance's settings. In the Dagster UI, navigate to Deployment > Configuration and verify that the run_queue key is set.
Runs remaining in QUEUED status
The possible causes for runs remaining in QUEUED status depend on whether you're using Dagster+ or Dagster Open Source.
- Dagster+
- Dagster Open Source
If runs aren't being dequeued in Dagster+, the root causes could be:
- If using a hybrid deployment, the agent serving the deployment may be down. In this situation, runs will be paused.
- Dagster+ is experiencing downtime. Check the status page for the latest on potential outages.
If runs aren't being dequeued in Dagster Open Source, the root cause is likely an issue with the Dagster daemon or the run queue configuration.
Troubleshoot the Dagster daemon
- Verify the Dagster daemon is set up and running. In the Dagster UI, navigate to Deployment > Daemons and verify that the daemon is running. The Run queue should also be running. If you used dagster dev to start the Dagster UI, the daemon should have been started for you. If the daemon isn't running, proceed to step 2.
- Verify the Dagster daemon can access the same storage as the Dagster webserver process. Both the webserver process and the Dagster daemon should access the same storage, meaning they should use the same
dagster.yaml. Locally, this means both processes should have the same setDAGSTER_HOMEenvironment variable. If you used dagster dev to start the Dagster UI, both processes should be using the same storage. Refer to the Dagster Instance docs for more information.
Troubleshoot the run queue configuration If the daemon is running, runs may intentionally be left in the queue due to concurrency rules. To investigate:
- Check the output logged from the daemon process, as this will include skipped runs.
- Check the max_concurrent_runs setting in your instance's dagster.yaml. If set to 0, this may block the queue. You can check this setting in the Dagster UI by navigating to Deployment > Configuration and locating the concurrency.runs.max_concurrent_runs setting. Refer to the Limit the number of total runs that can be in progress at the same time section for more info.
- Check the state of your run queue. In some cases, the queue may be blocked by some number of in-progress runs. To view the status of your run queue, click Runs in the top navigation of the Dagster UI and then open the Queued and In Progress tabs.
If there are queued or in-progress runs blocking the queue, you can terminate them to allow other runs to proceed.